博锐尚格 AI天天见六:强化学习算法应用探索
这是一个大街小巷热议人工智能的时代~
人工智能犹如上世纪九十年代的互联网,以惊涛之势席卷大江南北、带动着产业革命。
作为智慧建筑运维领域的专业服务商,有志于“用数字智能服务每个建筑,创造可持续的美好生活”,在智慧之光的感召下,博锐尚格在人工智能之路上苦苦探索。
深知于智慧之路上前行,不仅需要一往无前的勇气,还需要笃定、冷静,同时这一前探过程,绝不应该孤独的求索,博锐尚格CTO沈启博士整合博锐尚格在人工智能之路上的探索成果,以”AI天天见”系列文章与业界分享、讨论AI技术于智能建筑运维领域的应用之道。
理念解析:强化学习算法
强化学习是机器学习的一个重要分支,它受行为心理学启发,主要聚焦于智能单位如何在环境中采取策略从而最大限度地得到奖励。
强化学习主要由智能体(Agent)、环境(Environment)、状态(State)和动作(Action)、奖励(Reward)组成。
智能体将在环境的当前状态下,根据奖励信号做出动作,从而达到环境中的不同状态并得到奖励。
强化学习的过程就像是一个老师,他不会直接的告诉你一个东西的定义,不会直接的说“什么是什么”(区分于监督学习),也不会让你自学归纳(区分于无监督学习),而是一步步的引导,在你做出正确的逻辑判断时给予奖励,当你犯错时给予惩罚,直到最终推出最优的答案。强化学习目前有多种分类方式,譬如回合更新(Monte-Carlo update)和单步更新(Temporal-Difference update)、在线学习(On-Policy)和离线学习(Off-Policy)等。
Q-learning是强化学习算法中离线学习的一种算法,Q(s,a)是在环境中某一时刻的状态S,采取动作A能够获得的收益,智能体会根据其采取的动作获得回报,主要优势是使用了时间差分法能够进行离线学习, 使用Bellman方程可以对马尔科夫过程求解最优策略,核心思想是在不同状态下采取不同的行动构建一个Q-Table来存储Q值,从而获得最大收益。
博锐尚格应用探索:空调末端控制
强化学习可以应用到很多建筑机电系统和设备的控制上,以下是应用Q-learning学习算法到环境调节上的实例展示。
首先我们会初始化一个Q-table,用来存放我们的决策值;之后会根据当前所处的状态从Q-table中选取要采取的动作,执行该动作,并计算获取的收益;最后更新Q-table和状态,再根据新的状态选择动作,循环下去直到满足终止条件。
其中,更新Q-table的算法公式如下:

Qk+1是更新后的Q值,xk是状态值,uk是采取的动作,αk是学习率,γ是折扣因子,u’表示xk+1状态下所采取的动作。
图示是针对新风机控室内CO2的学习过程:在不同状态下控制动作从初始到收敛的学习的几张过程图。可以看出初始只预设了一种动作,逐渐学习得到不同CO2浓度的状态下,对应的不同控制动作。
这种基于人工智能学习的控制调节方法,改变了原有空调系统与人的交互方式,人们不再去设定一个自己看不懂的数字,而是反馈“是否舒适”,机器通过不断学习人的舒适反馈,自己学会了如何开空调,能够较好的提升用户的满意度。

(a)
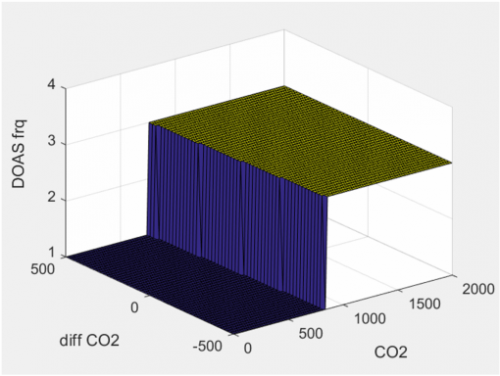
(b)

(c)

(d)
图一. 不同状态下控制动作的学习过程(a)-(d)从初始到学习完成收敛
应用成效:提升最终用户环境满意度
基于强化学习算法的空调末端控制已经在博锐尚格室内环境与健康主动管理解决方案中得到应用。
室内环境与健康主动管理解决方案是针对建筑室内空间环境管理,包含监测、报警、定位、控制、评估、改造的整体解决方案。该方案的应用,可以确保客户对于所有室内环境问题都完全知情、定位准确、处置过程在线可控,帮助业主通过工程缺陷改造或基于风险提示主动调整运行模式,避免环境问题,提升空间环境体验,进而提升租金收益、消除管理盲区,避免因环境或健康安全问题而造成的租金损失。
实践显示,基于强化学习算法的空调末端控制模型具有更好的自适应、自优化能力,很大程度地提高了控制精度(10%)和环境满意度(15%),同时可以在满足需求的前提下尽可能的节能减排。
结语
强化学习算法的探索与落地应用,有效的识别了智能运维的发展方向,解决了客户深层问题。“陪客户过日子”的道路上,博锐尚格沿“用数字智能服务每个建筑,创造可持续的美好生活”方向,又迈出坚实一步。博锐尚格也期望能与更多有识之士一起,能够探索更多的AI应用之道,推动行业不断进步~
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。